資料庫的效能監視器
這篇文章主要介紹幾個主要的 Performance Counters
如何運用最重要的幾個 Performance Counter 來對於資料庫效能做初步的分析
效能監控主要有四大類,分別為:
- 處理器 Processor
- 記憶體
- 磁碟
- SQL Server

處理器
- Processor (Total)
- Processor (sqlServer)
這兩個 Performance counter 主要可以看出處理器是否有效能上的瓶頸,
如果處理器有效能上的瓶頸,那麼是否主要是 SqlServer 造成
因此,我們可以將這兩個結果做比對分析,如下圖所示,
Processor (Total)與Processor(sqlServer)兩個圖型的波形相近,
這也表示該伺服器主要執行的應用程式為 SQL server

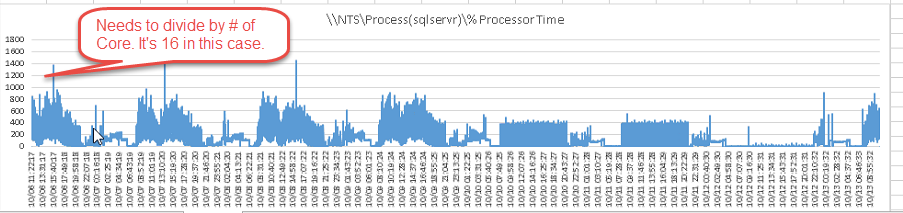
Processor counter 特別要注意的是 Y 軸
如果有 16 cores 的 CPU 時,必須要將 Y 軸的值除以 Number of Core
接著要介紹另外一個 Counter
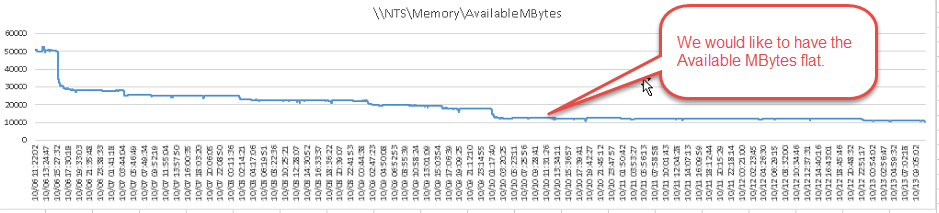
Memory\Available MB
這個指標主要告訴我們目前還有多少剩餘記憶體 MB
如果剩餘的記憶體MB 一直很少的話,也表示記憶體的效能瓶頸,
通常我們希望這個值可以長時間保持平穩。
Page Life Expectancy
另外一個衡量記憶體的指標為 Page Life Expectancy
這個值表示:平均資料可以停留在記憶體的時間(秒)
這個值越大,表示資料停留在記憶體的時間越長。這個值越小,表示記憶體空間時常不足,因此資料庫必須要時常將資料趕出(page out)記憶體。
這個值分析的結果,我們比較希望的圖形是:
- 最低值至少有 8 hour x 60 min x 60 sec = 28800 sec 以上
因為以上班時間 working hours 8 hour 來計算的話,我們希望上班時間的時候,大部份的資料都可以在記憶體中取得。
- 圖形上下的頻率與周期比較不密集
因為如果圖形的頻率與周期很密集的話,表示記憶體常常遇到不足的情況,經常有資料必須要被趕出記憶體 page in/out。
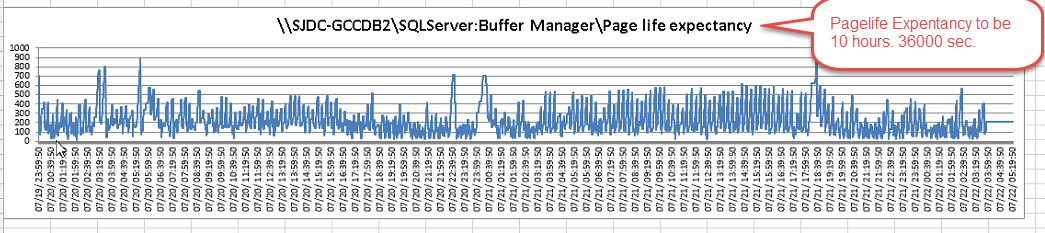
如下圖所示就是一個記憶體效能瓶頸的案例
因為
1. Page life Expectancy 最小值很多狀況下低於 100 sec
2. 低於 100 的次數與頻率很多
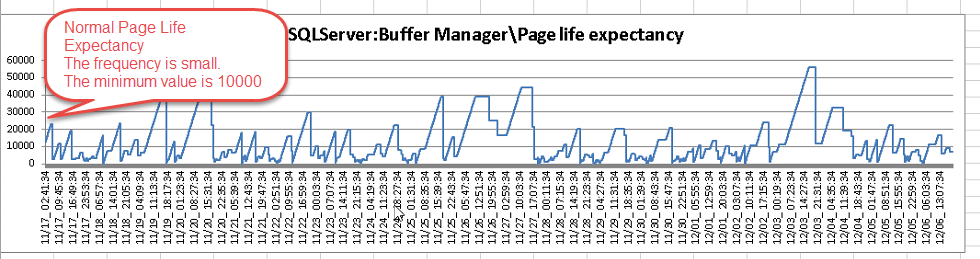
相對的,下圖 Page Life Expectancy 就是一個比較理想的記憶體配置。因為
1. Page Life Expectancy 最低值都有 1000以上
2. Page life Expectancy 變化的周期與頻率較長
記憶體的兩個重要的 Counters
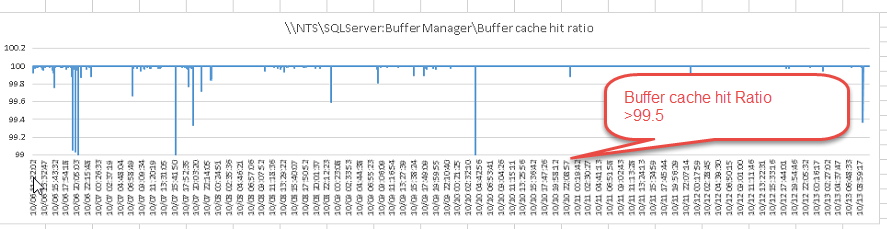
- Buffer Cache Hit Ratio
- Page Life Expectancy

Buffer Cache Hit Ratio
這是另一個觀察記憶體快取運用效率的指標,我們希望這個比率可以高於 99%
如果多半的資料庫資料可以在記憶體中取得,相對來說整體資料庫的效能會好很多。因為,如果資料庫無法在記憶體快取中取得資料的話,就必須到磁碟讀取。而到磁碟讀取的 disk I/O 相對會耗費比較多的時間。
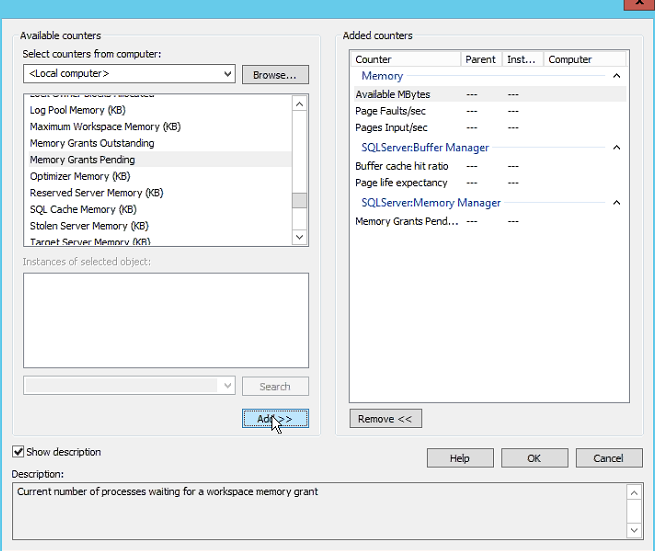
記憶體大小配置
- Total Server Memory
- Target Server Memory
Target Server Memory 的值主要是 SQL server Max memory 的設定
Total Server Memory 是SQL Server 所佔用記憶體的大小
隨著時間經過,這兩個值會逐漸趨於一致。

Disk Performance Counters
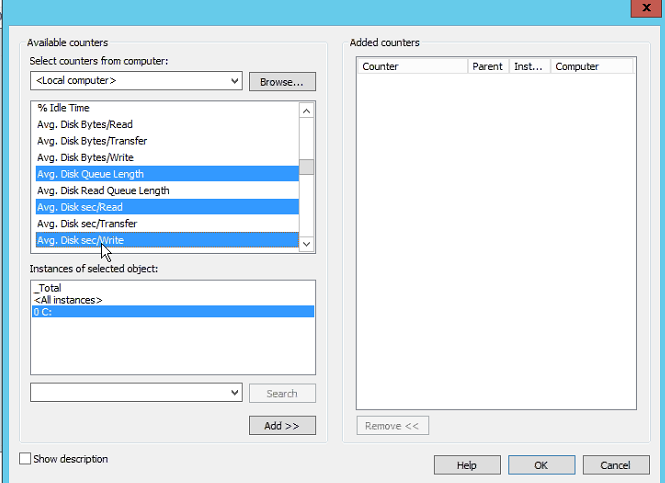
接下來要介紹幾個關於 Disk 的 Performance Couters
- Disk Queue Length
- Avg Disk sec/read
- Avg Disk sec/write
要注意的是,這些指標必須要指定所要觀察的磁碟 C, D or E
因為我們要觀察的是資料庫檔案所在的磁碟,如下圖所示,資料庫所在檔案在 C磁碟:

因此,效能監視器設定這些指標時,就必須指定 C 磁碟
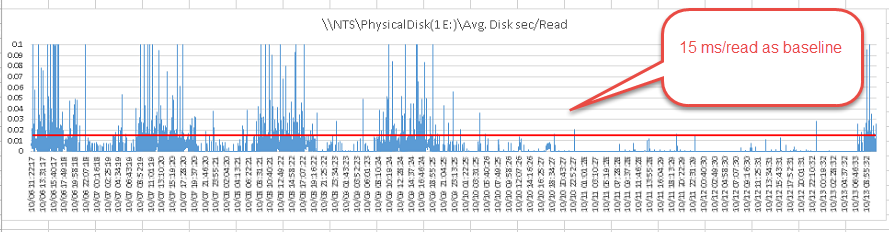
Avg Disk Sec
對於磁碟的讀取,我們會希望一個基準 15 ms/read,如下圖紅線 (15 ms/read) 所示:
Avg Disk Queue
這個值主要指的是有多少工作正在等待磁碟存取
我們會希望這個值越低越好,表示需要等待磁碟的工作很少
如下圖所示,就是一個我們所希望看到的,因為大部分的時間來說,磁碟等待的工作數量幾乎為 0。相反的,如果大部份的時間,磁碟等待的工作量都超過 50,那也表示磁碟的效能瓶頸
必須要進一步了解什麼造成磁碟瓶頸。有可能是 Table Scan 造成,有可能是不適當的 index,有可能是 Statistics 沒有更新,有可能是其他應用程式造成該伺服器資料讀取等。
