Linux Performance Monitoring and Tuning – vmstat個案討論

當做完效能測試的自動化測試之後,我們必須要監控的伺服器紀錄相關的效能。並且進一步分析。
這篇文章主要說明如何監控 Linux作業系統的效能。如何解讀每一個 Linux效能工具的輸出結果。
如何針對這些結果,做出效能瓶頸的結論與進一步的行動。
效能調教四大天王
四大天王:CPU、記憶體、磁碟讀取、網路
效能調教主要在於發現目前系統的瓶頸並且對於系統與應用程式做一些微調。
系統的效能調教之所以為科學也是藝術,主要原因是效能調教沒有一定的公式或是步驟。
因為效能調教主要在於取得一個符合目前系統負載的平衡。
這些平衡包含系統資源:CPU、記憶體、磁碟讀取、網路
因此,要釐清效能瓶頸,必須先釐清效能瓶頸在於 CPU、記憶體、磁碟與網路的哪一環節
效能的基準 Baseline / Benchmark
由於系統的運用效率與使用者的使用狀況、系統的規格等都有所關連。到底怎樣的效能是可預期的,怎樣的效能是需要調整。
必須要建立一定的效能基準與統計。這樣才有比較的基準與改善的依據。
這邊介紹一個工具 vmstat 與分析方法。
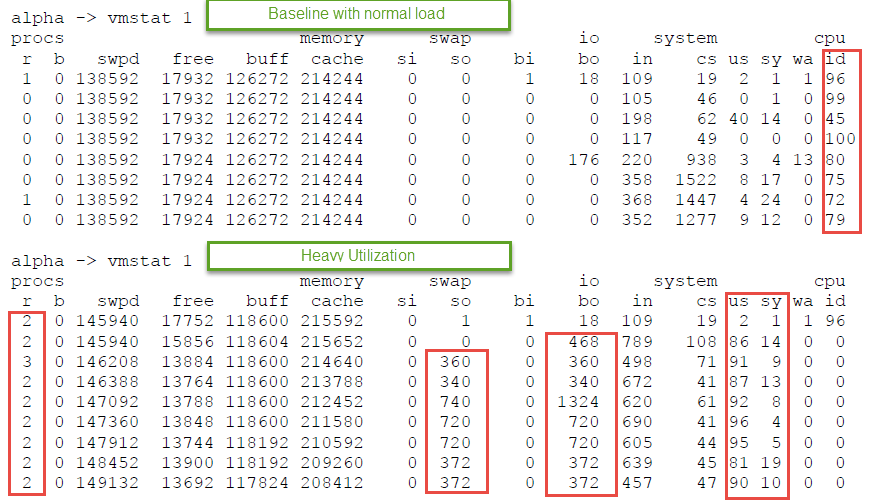
如下圖所示,CPU “id”,表示 “idle”的時間,框紅線處。
正常的 loading CPU Idle 時間為 72%~100% (儘管有特定時間為 45%)
Heavy 的使用狀況下,可以看出 CPU Idle 的時間大部分為 0 。
而 CPU “us”: User application time 與”sy” System Time,us + sy 兩者相加都接近 100。
為什麼會這樣了? 另外可以看出 swap 與 io 都有明顯的增加。初步的判斷可以知道,該 CPU主要忙於應用程式 (user) 所造成的大量檔案寫入。
例如:有可能是應用程式在處理大型檔案的解壓縮,需要耗用記憶體與 IO。當然也有可能是資料庫沒有適當的索引,造成 query 資料表所造成。
(資料參考http://www.strongmail.com)
CPU使用效率
如上圖 vmstat 有幾個指標可以看出 CPU 的使用效率
us: User Time – 這個值越高,表示CPU執行在使用者應用程式的比重越高。
sy: System Time – 如果CPU花在系統的時間比較多,通常表示相關的 Disk I/O比較高。
wa: Wait IO – 表示CPU等待IO 或是其他硬體資源的時間。
id: Idle – 這個值如果很高,也表示系統並不忙碌。十分的空閒。
另外,vmstat 第一欄的 “r”,也可以看出CPU的忙碌
r: Run Queues表示有多少的工作等待CPU執行。通常來說,這個值低於 CPU的總個數。
b: Blocked有多少工作被 Blocked.這個值多半為 0.
vmstat 個案討論1
觀察下列 vmstat 輸出結果,有什麼發現呢?
提示:框紅線的地方為數值比較異常忙碌的時候
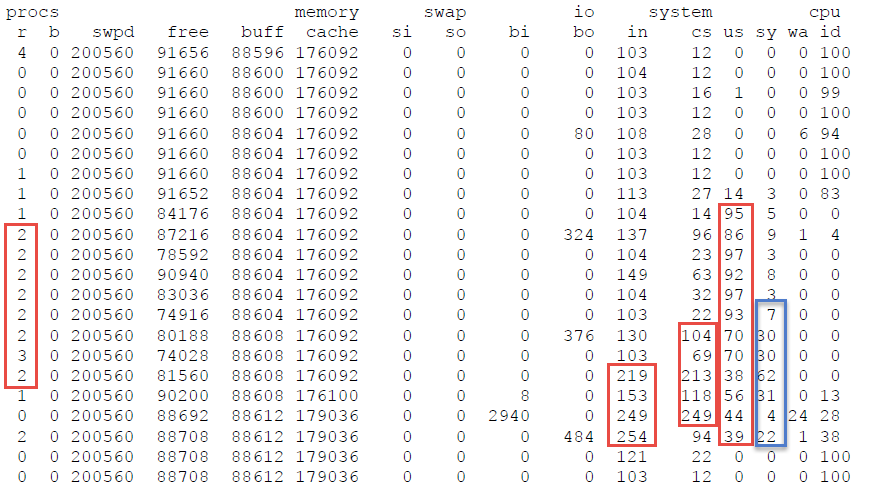
分析歸納為下列幾點
- run queue 最高的時候為 3,表示有些時候 CPU 為效能瓶頸。
- CPU 的使用在 User space 瞬間最高達到97但是之後慢慢趨緩
- wa (CPU 等待磁碟的時間) 與 in 瞬間於後期飆高,表示該應用程式有可能在最後做檔案一次寫入的動作。
- 一開始CPU 使用很高的情況下, context switches並沒有很明顯的相對提高,表示有可能當時應用程式使用 single thread 來處理。
vmstat 個案討論2
再看看下列的例子,是否有什麼發現?
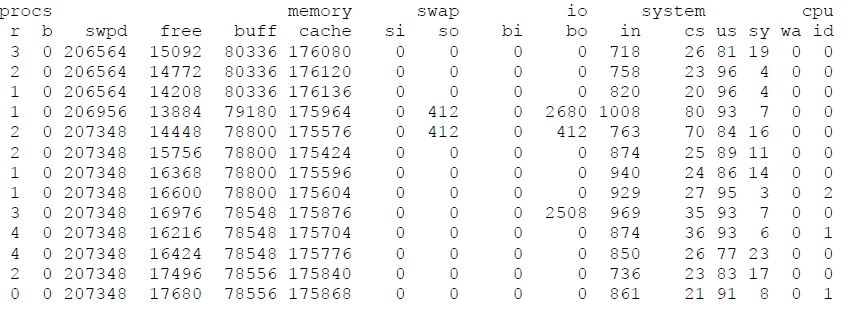
- in (interrupts) 一直維持很高,表示處理許多硬體或是磁碟的 IO.
- cs (context switch)很低:表示 single thread 或是 single process。
- us (CPU usage with user application ): 一直維持在 81-95%高使用率。
- r (run queue): 有時候會有比較多工作 3~4工作等待 CPU 執行。
vmstat 個案討論3
再看一個例子
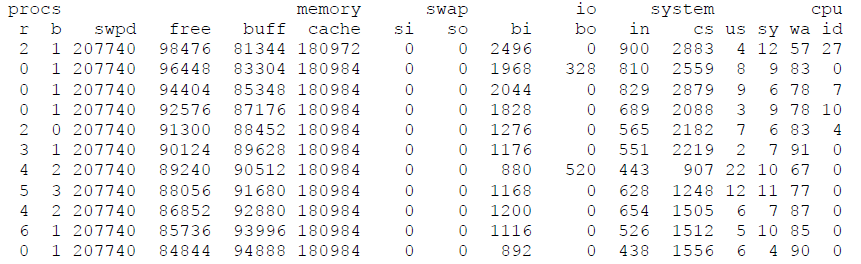
這個例子中 cs (context switches)異常的高於 in (interrupts)表示CPU 花很多時間在做 context switching threads,
這也表示該程式用了大量的 multiple threads。每個 thread 都在爭取 CPU執行的時間。CPU 不斷的在這些 thread 切換執行。
因為大量的 cs 會造成 CPU 運用效率的不平衡。也會造成wa (waiting)的提高。當然也會導致 us (CPU on user application )很低。
因為”b” (blocked)的值不等於0,表示有許多的工作被阻礙或是等待執行。
因此,要對於該程式進一步的 profiling 看看是哪些 thread 造成 context switches 與相關的資料內容。
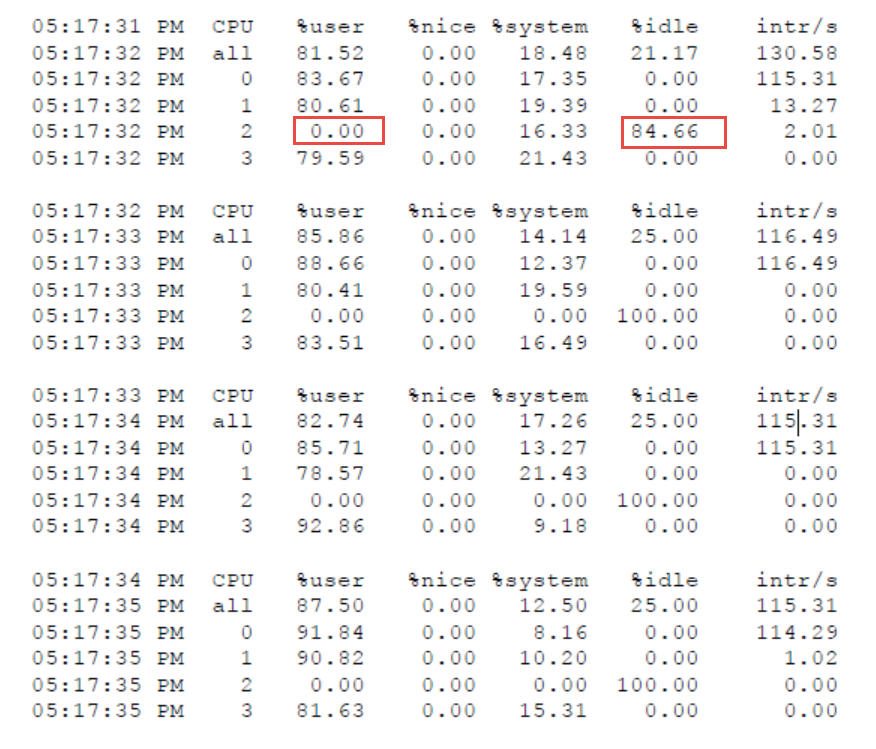
多個CPU的效能
要監控多個 CPU效能,可以透過下列指令
| mpstat –P ALL 1 |
這個例子可以知道:有四個CPU
CPU 0 and 1忙碌於使用者應用程式
CPU 2 大部分時間 Idle
CPU3 還有忙碌於系統的時間
vmstat 個案討論4
這個案例主要為,Disk IO很高的個案。
- Disk IO 很高的時候,主要的特徵是 “wa”很高,等待 disk I/O。同時 “b”很高,因為很多工作被 blocked.
- bi (disk blocks paged in)值很高:這表示資料快取的空間逐漸提升。
- free: free memory 維持於 17MB。儘管bi 資料從磁碟讀取進入記憶體,逐漸提升。
- buff 那麼所需要的記憶體從哪裡來呢? 從buffer 來,因為 buff (read/write buffers) 逐漸漸少。
- so (write dirty page to device)這表示對於虛擬記憶體的使用逐漸提高。
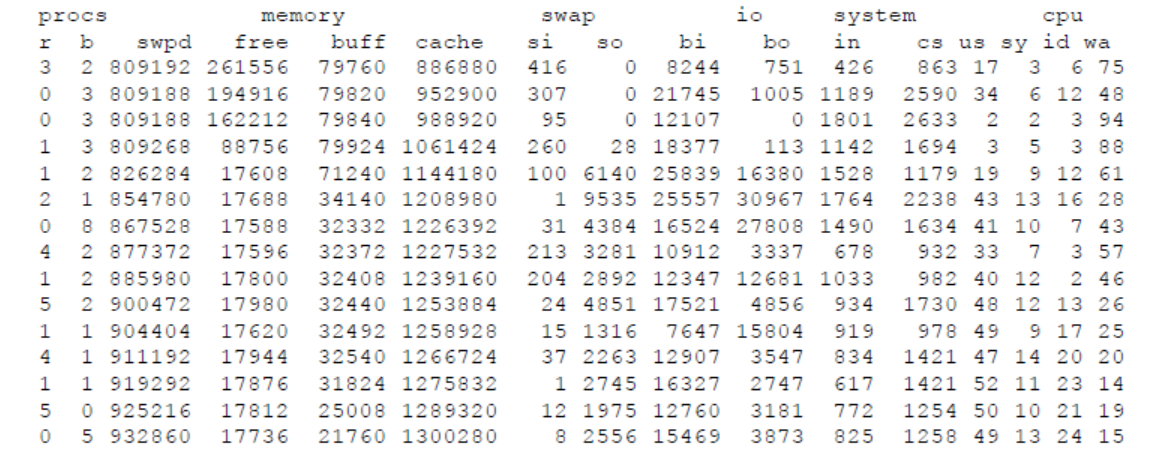
vmstat 個案討論5
- “wa” 都超過 50%,表示CPU 等待 IO 完成。CPU等待 IO完成之前,應用程式並無法繼續完成其他動作。因此 b (blocked) threads 的數量也會隨之提高。
- 另外要特別注意的是,這個例子中bi (disk block read into memory)很高,但是 bo 卻為 0,表示系統有大量的 IO 從磁碟讀取到記憶體 。
