Selenium網頁自動化測試:如何讀取網頁上的連結?
這篇文章主要說明網站自動化測試時,如何讀取網頁上的連結的幾種情況。
用 Selenium/Java 一個簡單程式實作示範。
如何讀取連結上的文字? 如何找到網頁上有特定關鍵字的聯結?
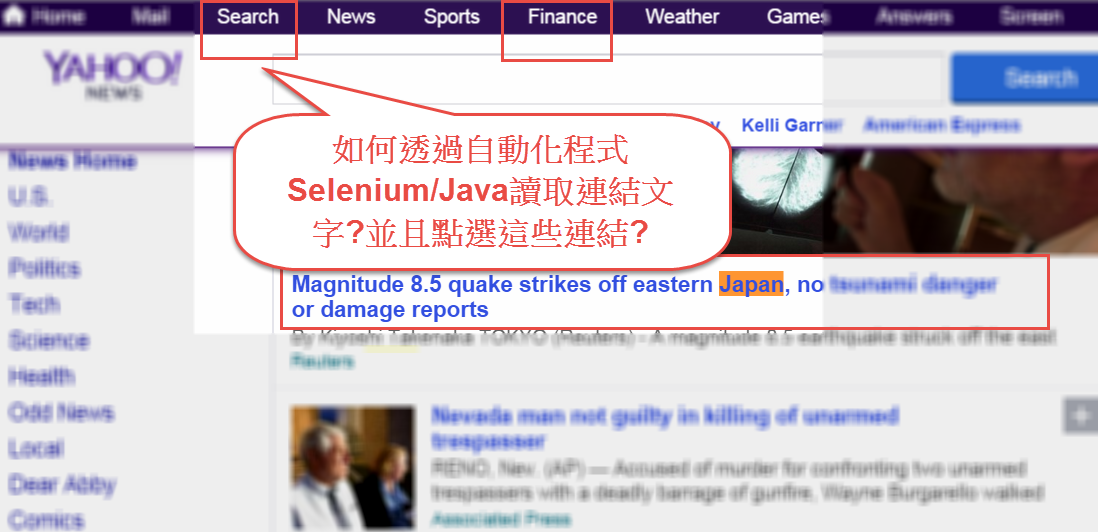
程式說明
讓自動化程式預設等待 10秒.
為什麼要做預設等待的動作呢? 因為網頁的載入時間不一致。
因此這個等待十秒,當自動化程式所指定的網頁元件暫時找不到的時候,就會等待十秒,
如果十秒內可以找到,那麼程式就會繼續。
但是如果十秒後還是找不到該網頁元件,那麼程式就會出現異常。網頁元件找不到
| driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS); |
啟動瀏覽器
這段程式主要是啟動瀏覽器,並且直接到該網址。news.yahoo.com
| driver.get(“https://news.yahoo.com/”); |
這段程式是啟動瀏覽器之後,將視窗最大化。
視窗最大化主要是讓我們更容易觀察。並不會影響測試結果。
| driver.manage().window().maximize(); |
其他程式說明,參見程式範例如下:
[pastacode lang=”java” message=”Handle links in Java/Selenium” highlight=”” provider=”manual”]
package mySelenium;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.support.ui.WebDriverWait;
public class Links {
public static void main(String[] args) {
//開啟 FireFox
WebDriver driver = new FirefoxDriver();
//預設等待時間十秒
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
//瀏覽至 news.yahoo.com
driver.get("https://news.yahoo.com/");
//將視窗最大化
driver.manage().window().maximize();
//選取Yahoo 最上方的 menu, News
String text =driver.findElement(By.xpath(".//*[@id='yucs-top-news']/a")).getText();
//列印出 news上面的連結文字
System.out.println(text);
//選取Yahoo 最上方的 menu, Weather
text=driver.findElement(By.xpath(".//*[@id='yucs-top-weather']/a")).getText();
//列印出連結文字
System.out.println(text);
//driver.findElement(By.linkText("Russian hackers behind $50 million IRS scheme, report says")).click();
// 選取網頁中含有 Japan 的連結
WebElement linkElement = driver.findElement(By.partialLinkText("Japan"));
// 找到之後,將整個連結的文字內容印出
System.out.print(" Here is the link text contains 'Japan': " + linkElement.getText());
// Close the browser when it's done
driver.close();
}
}[/pastacode]